

LLM初心者が最初に気をつけたい5つのこと
すべてはアイデアから始まります。
―― 「便利さ」に流されず、安心して使うための運用チェック
LLM(大規模言語モデル)を触り始めると、
想像より自然な文章が返ってきて、
驚くことがあります。
一方で、その自然さのせいで、
「どこまで信じていいのか」が曖昧になり、
不安が増えることもあります。
第1話では、LLMが
「次に来る確率が高い言葉」をつないで文章を作る、
という原理と、そこから見える原則を整理しました。
第2話では、そこから一歩進めて、
AI初心者がつまずきやすい点を
「運用のチェック」として5つにまとめます。
ここで残したいのは、
正解ではなく、迷ったときに戻れる「基準」です。
この記事で分かること
- 初心者が最初に意識したい注意点(5つ)
- 出力をうのみにしないための、確認の型
- 入力する情報を守るための、最低限の考え方
- Notionに残せる、短いチェックリスト
最初に、記事全体を1枚で俯瞰します。
細部はあとからで大丈夫です。
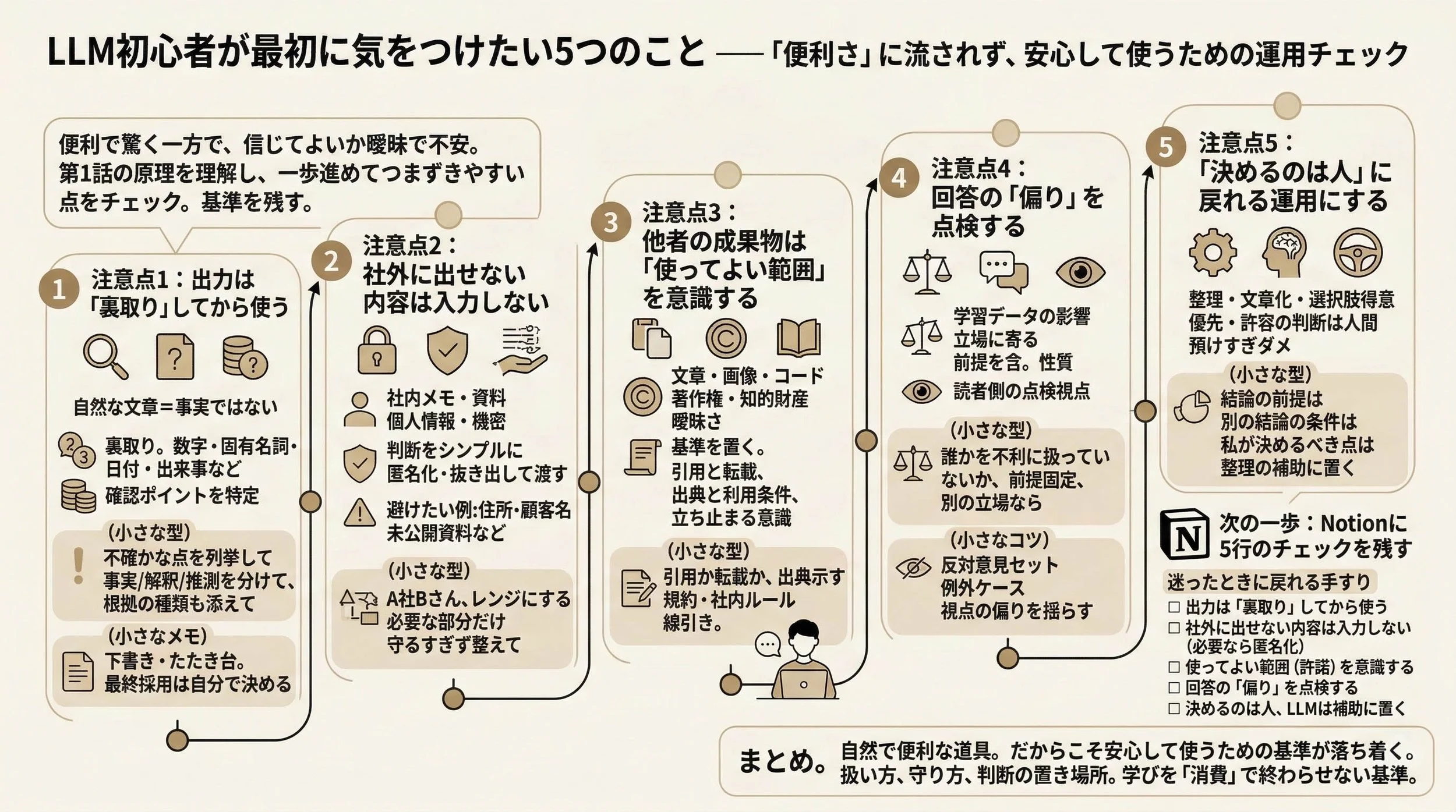
※ 「LLMを安心して使うために、初心者が押さえたい5つの運用チェックを1枚にまとめた全体図です。」
読み進めて迷子になったら、
ここに戻って「今どこを読んでいるか」だけ
確認してみてください。
ここから先は、
グラレコの「注意点1」から順に、
本文でほどいていきます。
注意点1:出力は「裏取り」してから使う
LLMの文章が整っているほど、
内容まで正しいように見えることがあります。
けれど、文章の自然さと、
事実としての正しさは別です。
特に、次のような要素が含まれるときは、
「先に確認が必要な箇所」を見つけておくと安心です。
- 数字(割合、順位、金額、統計)
- 固有名詞(人名、会社名、制度名、製品名)
- 日付や出来事(いつ、何が起きたか)
ここでのコツは、
全部を疑うことではありません。
「確認すべき場所」を先に特定して、
そこだけ丁寧に確認する、という運用です。
(小さな型)確認ポイントを先に出させる
- 「不確かな点があれば、先に列挙してください」
- 「事実/解釈/推測を分けて書いてください」
- 「根拠の種類(一次情報/一般論/経験)も添えてください」
(小さなメモ)
LLMの出力は、
「下書き」や「たたき台」として受け取り、
最終的な採用は自分で決める、
という距離感が持ちやすいです。
ここまでの感覚を、
短い絵で眺めるとこうなります。

※ 原理と原則を、10コマで「順番に」つかめる要点まとめです。
細部は忘れても大丈夫です。
「まず裏取り」という基準だけ、
手元に残っていれば十分です。
注意点2:社外に出せない内容は入力しない
LLMに相談するとき、
つい、メモや資料をそのまま入力したくなることがあります。
ただ、入力した内容には、
個人情報や機密が混ざりやすいです。
ツールや契約形態によって取り扱いは変わるため、
一律に断定することはできません。
だからこそ初心者の段階では、
判断をシンプルにしておくと安心です。
- 社外に出して困る情報は、最初から渡さない
- 必要なら、匿名化してから相談する
避けやすい例を挙げると、次のようなものです。
- 住所、電話番号、個人メール、ID、パスワード
- 顧客名、取引先名、担当者名
- 未公開の資料、社内の議事録(固有名詞つき)
(小さな型)入力前の置き換え
- 固有名詞を「A社」「Bさん」に置き換える
- 数字をレンジにする(例:1,234万円→約1,000万円台)
- 目的に必要な部分だけ抜き出して渡す
「守りすぎると使えない」ではなく、
「必要な形に整えて渡す」と考えると、
使いやすさと安心感が両立しやすいです。
注意点3:他者の成果物は「使ってよい範囲」を意識する
LLMは文章や画像、コードなど、
さまざまな形の素材を扱えます。
その分、著作権や知的財産の扱いが、
曖昧になりやすい場面も出てきます。
ここも、難しく考えすぎなくて大丈夫です。
初心者のうちは、次の基準を置くだけで整理しやすくなります。
- 引用と転載を混同しない
- 出典と利用条件(許諾)の意識を持つ
- そのまま流用する前に、一度立ち止まる
(小さな型)確認の問いを1つ入れる
- 「これは引用で足りるか、それとも転載になるか」
- 「出典を示す必要があるか」
- 「利用規約や社内ルールに触れていないか」
この話は、
「やってはいけない」を増やすためではありません。
安心して使い続けるために、
あらかじめ線引きを意識しておく、という意味です。
注意点4:回答の「偏り」を点検する
LLMは学習データの影響を受けるため、
出力が特定の立場に寄ったり、
見えにくい前提を含んだりすることがあります。
これは、悪意があるという話ではなく、
仕組みとして起きうる性質です。
だからこそ、読者側が
「点検する視点」を少し持っていると安心です。
(小さな型)偏りを見つけるチェック
- 「この文章は、誰かを不利に扱っていないか」
- 「前提が一つに固定されていないか」
- 「別の立場なら、どう見えるか」
(小さなコツ)反対意見をセットで出させる
- 「反対の立場なら、どこを指摘しますか」
- 「例外になりやすいケースはありますか」
点検の目的は、
LLMを疑い続けることではありません。
自分の判断を守るために、
視点の偏りを一度だけ揺らす、という感覚です。
注意点5:「決めるのは人」に戻れる運用にする
LLMは、整理や文章化、
選択肢を出すことが得意です。
その一方で、
何を優先するか、どこまで許容するか、
という判断は、あなた側に残ります。
ここをLLMに預けすぎると、
「もっともらしい結論」に引きずられやすくなります。
(小さな型)判断を取り戻す質問
- 「この結論が成り立つ前提は何ですか?」
- 「別の結論にするなら、どんな条件が必要ですか?」
- 「私が決めるべき点はどこですか?」
運用としては、
LLMを「回答者」ではなく、
「整理の補助」に置く方が安定しやすいです。
ここまでの5つを、
1枚の絵としてまとめて眺めると、
こういう全体像になります。
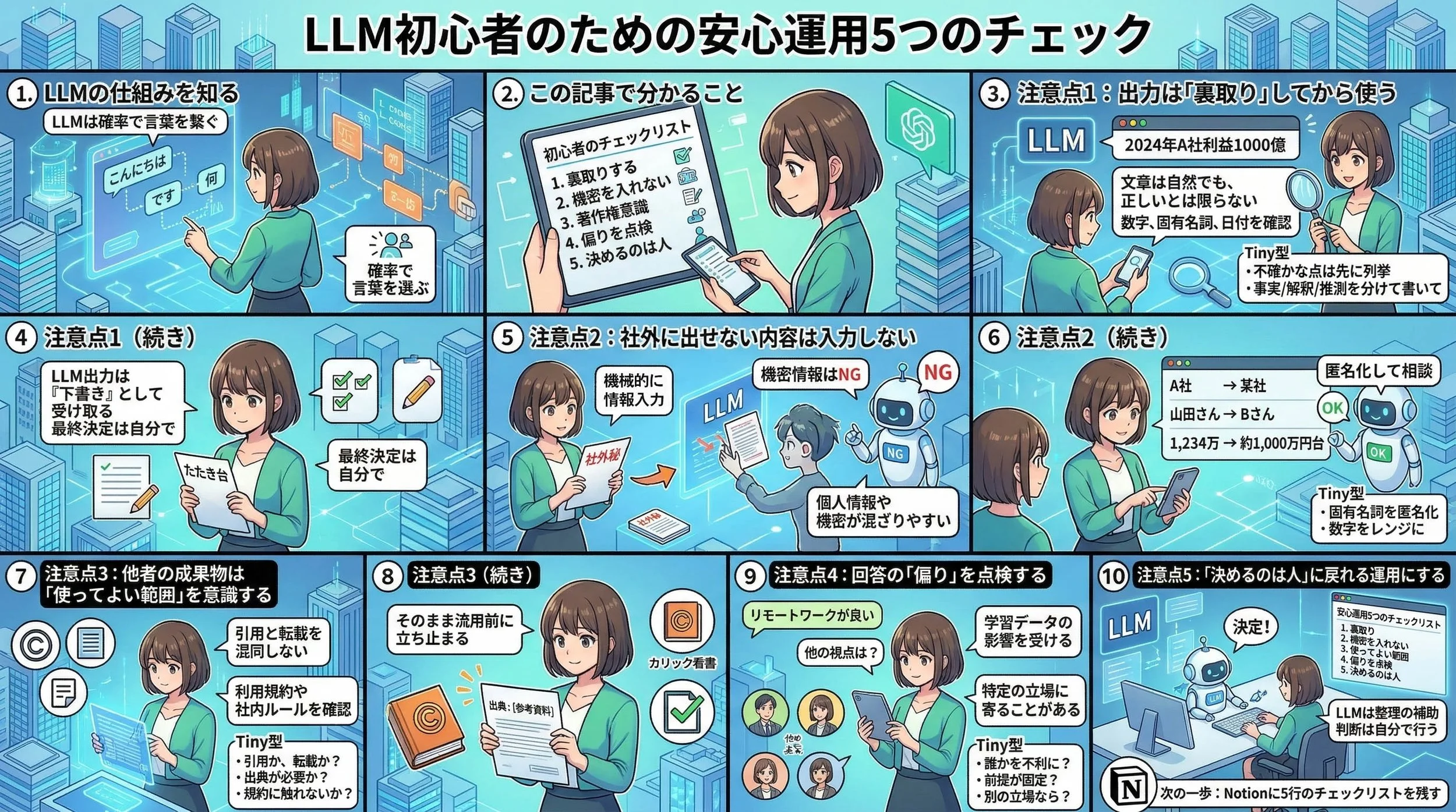
※ 5つの注意点を、場面ごとの具体例で“どう使えばいいか”まで追える10コマのまとめ図です。
忙しいときは、
この1枚だけ見返しても大丈夫です。
「次に何を確認すればいいか」が戻ってきやすくなります。
次の一歩:Notionに5行のチェックを残す
全部を覚えようとしなくて大丈夫です。
迷ったときに戻れる場所があるだけで、
使い方は落ち着きます。
Notionに1ページ作って、
次の5行だけ残してみてください。
- 出力は「裏取り」してから使う
- 社外に出せない内容は入力しない(必要なら匿名化)
- 使ってよい範囲(許諾)を意識する
- 回答の「偏り」を点検する
- 決めるのは人、LLMは補助に置く
この5行は、知識というより、
自分を守るための「手すり」です。
まとめ
LLMは、自然な文章を返してくれる便利な道具です。
だからこそ初心者の段階では、
「便利に使う」より先に、
安心して使うための基準があると落ち着きます。
今回の5つは、
出力の扱い方と、入力の守り方、
そして判断の置き場所を整えるためのチェックです。
よければNotionに5行だけ残して、
迷ったときの戻り先にしてみてください。
学びが「消費」で終わりにくくなります。

LLMの原理と原則
すべてはアイデアから始まります。
―― 仕組みを知って、振り回されないための最初の基準
LLM(大規模言語モデル)という言葉を、
目にする機会が増えました。
けれど調べ始めると、専門用語が多く、
どこから掴めばいいか分からなくなることがあります。
この記事では、LLMを「使いこなす」前に、
まずは原理(仕組み)と、
そこから見えてくる原則(動き方の傾向)を整理します。
読後に残したいのは、正解ではなく、
自分で判断するための「基準」です。
この記事で分かること
- LLM(大規模言語モデル)の基本的な定義
- LLMの「原理」(なぜそう動くのか)
- 原理から導かれる「原則」(起きやすいふるまい)
- 「平均的な答え」に寄る理由と、扱うときの考え方
- プロンプトとコンテキスト(文脈)の違い
- 精度を上げるための入口(RAGの考え方)
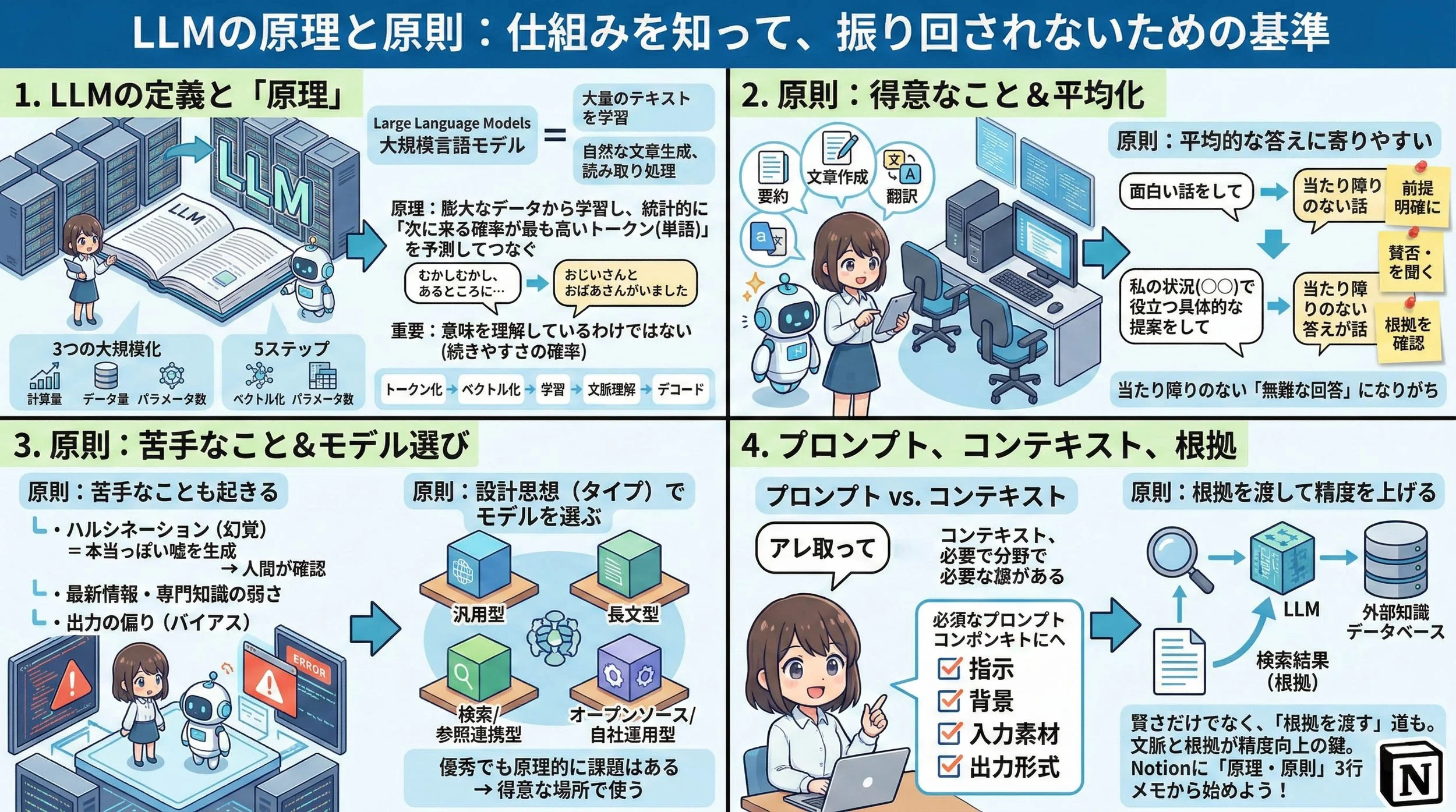
最初に、この記事全体を1枚で俯瞰します。
細部はあとからで大丈夫です。
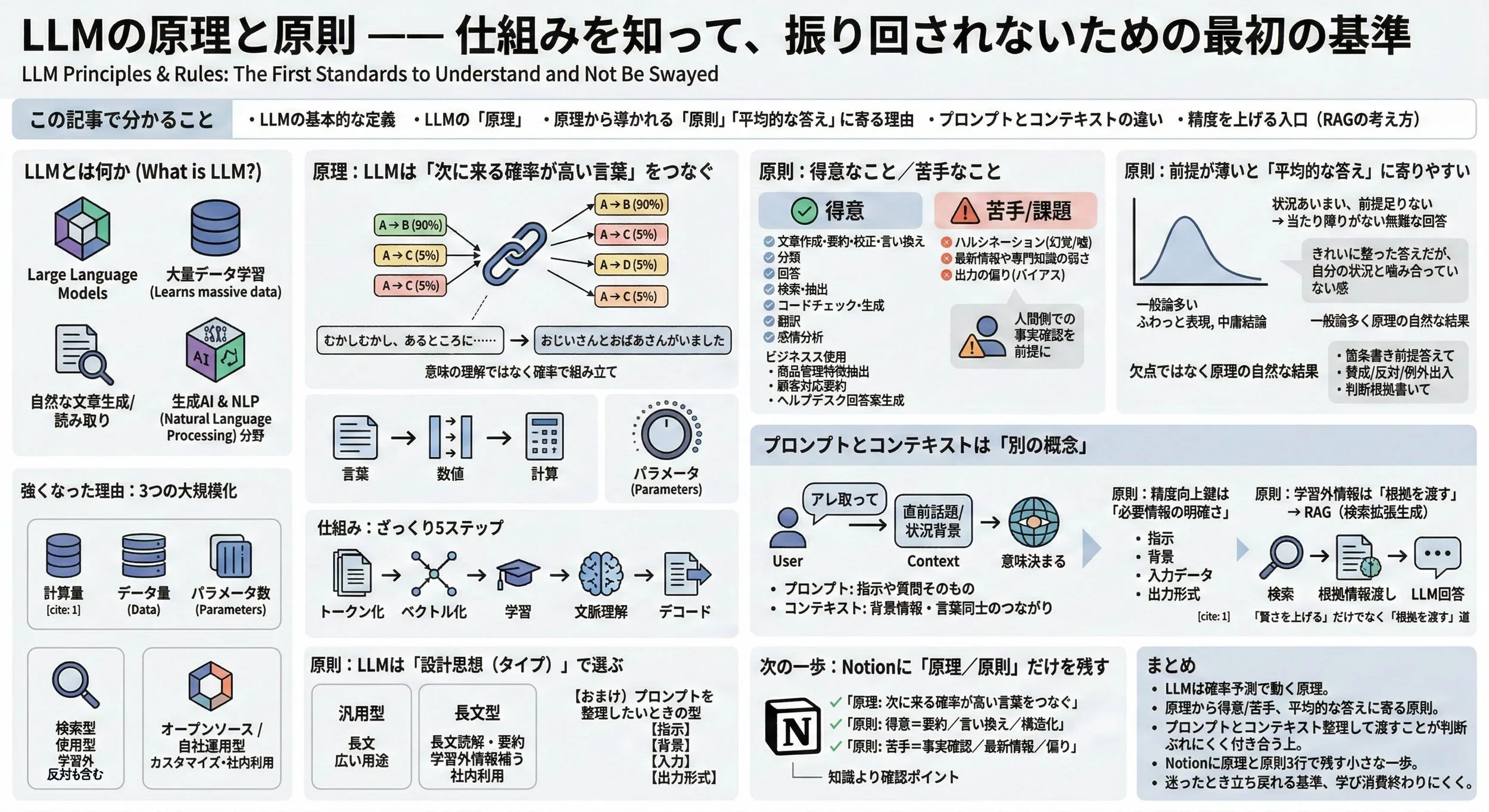
※ LLMを「原理→原則→扱い方」まで一枚で俯瞰できる全体図です。
読み進めて迷子になったら、
ここに戻って「今どこを読んでいるか」だけ確認してみてください。
LLMとは何か
LLM(大規模言語モデル)とは「Large Language Models」の略称で、
大量のテキストデータを学習することで、
自然な文章を生成したり、
文章を読み取るような処理を行えるAIモデルのことです。
ChatGPTをはじめとする多くのAIツールで、
中心的な役割を担っています。
LLMは、新しいコンテンツを生み出す「生成AI」の枠組みに含まれる技術の一つであり、
人間の言語をコンピューターで扱う
「NLP(自然言語処理)」分野の手法の一つでもあります。
原理:LLMは「次に来る確率が高い言葉」をつなぐ
LLMの原理は、一言で言えば、
「膨大なデータから学習し、統計的に
『次に来る確率が最も高い単語(トークン)』を予測して
つなぎ合わせる」
という仕組みにあります。
たとえば、日本の昔話には、
よく決まった“型”があります。
「むかしむかし、あるところに……」
と来たら、続きとして
「おじいさんとおばあさんがいました」
が出てきても不自然ではありません。
LLMは、この「型」を暗記しているというより、
大量の文章の中で
そう続くことが多いという傾向を学習しています。
だから入力がこの型に近いほど、
「それっぽい続き」を出しやすくなります。
ここで大事なのは、
LLMが昔話の意味を理解しているから、
この続きを出しているわけではない、という点です。
あくまで「続きやすさ」の確率で、
文章を組み立てています。
ここまでの話を、
8コマで眺められる形にするとこうなります。
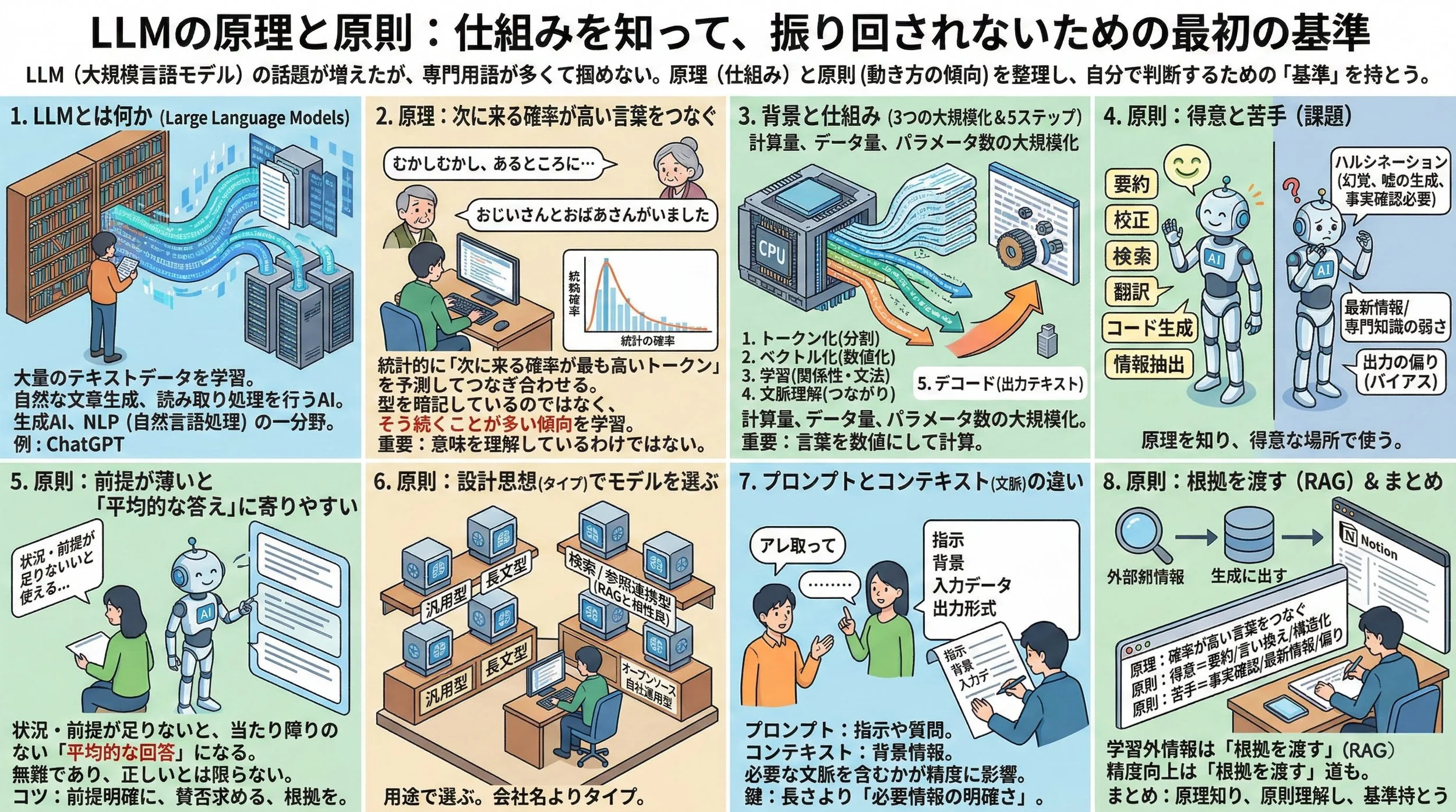
※ 原理と原則を、10コマで「順番に」つかめる要点まとめです。
読み終えて「細かい用語が残っているな」と感じても、
まずは「原理はこれ」と掴めていれば十分です。
背景:LLMが強くなった理由は「3つの大規模化」
従来よりも次の3つが大幅に強化されたことで、
文章生成や質問応答などの精度が向上してきました。
- 計算量:コンピューターが処理する仕事量
- データ量:学習に使われるテキスト情報量
- パラメータ数:モデルの挙動を制御する係数の集合体
「規模が大きい=万能」ではありません。
ただ、性能が伸びた理由を理解するための背景として、
押さえておくと迷子になりにくいです。
仕組み:LLMは、ざっくり5ステップで動く
LLMは、人間の脳の神経回路をまねたニューラルネットワークを用いて、
深層学習(ディープラーニング)を行っています。
入力されたテキストは、ざっくり次の流れで処理されます。
- トークン化:入力文を最小単位に分割する
- ベクトル化(埋め込み):トークンを数値(ベクトル)に変換する
- 学習:単語の出現や関係性、文法的な構造などを学習する
- 文脈理解:プロンプト内の関連性やつながりを計算する
- デコード:出力用のテキストへ変換して出力する
ポイントは、
LLMは「言葉」をそのまま扱っているのではなく、
すべて数値に変換して計算している、ということです。
用語:パラメータはLLMのふるまいを決める“調整つまみ”
この仕組みを支えているのが、膨大な数の**「パラメータ」**です。
パラメータはモデルの挙動を制御する“調整つまみ”のようなもので、
規模が大きいほど、表現の幅が広がる方向に働きます。
パラメータは「埋め込み」「重み」「バイアス」などで構成され、
訓練を通じて単語の意味や関係性を数値として持つようになります。
原則:原理が同じなら、得意なことも見えやすい
LLMは、テキストに関連する幅広いタスクを実行できます。
- 文章の作成・要約・校正・言い換え
- 文章の分類
- 質問に対する回答
- 情報の検索・抽出
- プログラムのコードチェック・自動生成
- 多言語翻訳
- 感情分析
ビジネスでは、たとえば次のような形で使われます。
- 商品管理:商品情報から特徴を抽出し、カテゴリ分類を補助する
- 顧客対応:対話記録を要約し、業務負荷を軽減する
- ヘルプデスク:ナレッジから関連情報を探し、回答案を生成する
原則:同じ原理だからこそ、苦手なことも起きる
優秀な一方で、原理的に抱えやすい課題もあります。
- ハルシネーション(幻覚):
事実に基づかない情報や、本当っぽい嘘を生成してしまうことがあります。
そのため、事実確認が必要な場面では、
人間側での確認を前提にしておくと安心です。
- 最新情報や専門知識の弱さ:
あらかじめ学習済みのデータをもとに回答するため、
学習範囲外の最新情報や、高度な専門性が強い領域では弱さが出ることがあります。
(検索機能と連携したモデルなどは例外があります)
- 出力の偏り(バイアス):
インターネット上のデータを学習するため、
偏りを吸収し、倫理的に問題のある回答を出すリスクがあります。
ここで大切なのは、
「LLMがダメ」という話ではなく、
原理を知った上で、得意な場所で使うという距離感です。
原則:前提が薄いと「平均的な答え」に寄りやすい
LLMは、基本的に「次に来る確率が高い言葉」をつないで文章を作ります。
そのため、状況があいまいだったり、前提が足りなかったりすると、
多くの人に当たり障りがない“平均的な回答”に寄ることがあります。
きれいに整った答えが返ってくるほど、
どこか「自分の状況と噛み合っていない」感じがすることがあります。
この感覚を、4コマにするとこんな雰囲気です。
※ 4つのポイントで、LLMの「原理→原則→使い方」を短く確認できるまとめ図です。
ここで言う「平均的」は、
必ずしも「正しい」という意味ではありません。
外しにくい言い方(無難なまとめ方)になりやすい、という性質です。
たとえば、こんな形で現れます。
- 具体策よりも、一般論の整理が多くなる
- 断言を避けて、ふわっとした表現が増える
- 反対意見や例外が出にくく、
「中庸(ちゅうよう=ほどほど)」に見える結論になる
これは欠点というより、
LLMが「それっぽい続き」を選ぶ原理の自然な結果です。
だからこそ、前提(条件)を渡すほど、
回答の解像度が上がりやすくなります。
(小さなコツ)平均化を弱めたいときの聞き方
- まず「前提」を箇条書きにしてから答えてください
- 賛成/反対/例外をそれぞれ出してください
- 結論の前に、
判断に使った根拠(どの情報に依存しているか)を書いてください
原則:LLMは「名前」より「設計思想(タイプ)」で選ぶ
LLMは、会社名やシリーズ名が変わっても、
大まかなタイプ(得意領域)は残り続けます。
どのモデルが良いかは状況で変わるので、
まずは「タイプ」で見立てておくと判断しやすくなります。
- 汎用型:広い用途に対応しやすい
- 長文型:長い文章の読解・要約に強い傾向がある
- 検索/参照連携型:学習外の情報を補いやすい(RAGと相性が良い)
- オープンソース/自社運用型:カスタマイズや社内利用に寄せやすい
プロンプトとコンテキストは「別の概念」
ここからは、LLMを使う側の視点です。
- プロンプト:ユーザーが入力する指示や質問そのもの
- コンテキスト(文脈):その指示を成立させる背景情報や、言葉同士のつながり
人間の会話でも、
「アレ取って」という言葉だけでは伝わりません。
直前の話題や状況(文脈)があって、
ようやく意味が決まります。
LLMにとっても同じで、
プロンプトの中に、必要な文脈が含まれているかが精度に影響します。
原則:精度を上げる鍵は「長さ」より「必要情報の明確さ」
プロンプトは、ただ長ければ良いわけではありません。
けれど、意図を正確に伝えるために必要な情報を入れると、
結果として長くなることはあります。
たとえば、次の要素が整理されていると、
LLMは迷いにくくなります。
- 指示(何をしてほしいか)
- 背景(誰向けか/目的は何か)
- 入力データ(素材となる文章など)
- 出力形式(箇条書き、文字数、トーンなど)
原則:学習していない情報は「根拠を渡す」で補える(RAG)
LLMは、プロンプト内の情報と、学習済みの知識をもとに回答します。
そのため、社内データや最新情報など、学習していない情報は苦手です。
そこで使われるのが、RAG(検索拡張生成)という考え方です。
関連情報を検索し、
その「検索結果(根拠情報)」を新たなコンテキストとしてLLMに渡します。
つまり、精度の方向性としては、
「賢さを上げる」だけでなく、「根拠を渡す」という道もあります。
次の一歩:Notionに「原理/原則」だけを残す
ここまでを読んで、
すぐに何かを極める必要はありません。
よければ、小さく残しておくところから始めてみてください。
Notionに「LLMの原理と原則」という1ページを作って、
次の3つだけ書きます。
- 「原理:次に来る確率が高い言葉をつなぐ」
- 「原則:得意=要約/言い換え/構造化」
- 「原則:苦手=事実確認/最新情報/偏り(平均化も起きうる)」
この3行は、知識というより、
LLMの出力を受け取るときの「確認ポイント」です。
(おまけ)プロンプトを整理したいときの型
必要なら、次のように
「指示」と「素材」を分けて書くと混乱しにくくなります。
【指示】
以下の文章を、初心者向けに200〜300文字で要約してください。
箇条書きで、重要点を3つに絞ってください。
【背景】
読者はAIに興味があるが、専門用語が苦手です。
【入力】
(ここに文章を貼る)
【出力形式】
- 要点1:
- 要点2:
- 要点3:まとめ
LLMは、膨大なテキストから学習し、
「次に来る確率が高い言葉」を予測してつなぐ、という原理で動きます。
その原理から、
得意なこと/苦手なこと、
そして「平均的な答え」に寄りやすい場面がある、という原則も見えてきます。
だからこそ、プロンプトとコンテキストを整理して渡すことが、
LLMと付き合う上で、判断がぶれにくくなります。
もしよければ、今日の小さな一歩として、
Notionに「LLMの原理と原則」を3行で残してみるのも一つです。
迷ったときに立ち戻れる基準があるだけで、
学びが「消費」で終わりにくくなります。